Did you know that Google deals with around 8.5 billion searches every day?
That means there are 8.5 billion chances for your website to be found by the search engine. And what decides the discoverability of your website is something as simple as a text file, which essentially, is no larger than a normal text message.
Behold, robots.txt. Your unsung hero (or even villain) of search engine optimization (SEO).
Though small in size, this .txt file plays a vital role in molding your website’s online presence and ranking in search engine results pages (SERPs). Regardless of whether you are running a large e-commerce company or a small travel blog, understanding robots.txt is what will eventually make the difference regarding its success. A leading organic SEO company can help you implement best practices for elevating your SERP rankings.
What exactly is robots.txt and how does it matter for SEO? Let us take a dive into the details.
What is Robots.txt?
Robots.txt is a simple file situated at the root directory of a website, that contains a set of commands for web crawlers (e.g, Googlebots), on how they should crawl (or not crawl) and index a website’s content.
Most websites don’t need a robots.txt file. That’s because search engines can automatically find and index all important pages in a website. Then, why do you need one?
Well, like mentioned before, scenarios will arise when you will need to tell the search engines what NOT to crawl. For instance, you’d want the bots to ignore private pages like a staging page or an internal search results page where you wouldn’t want your audience to land on. In such cases, you can use robots.txt file to block these pages from being crawled by search engine bots.
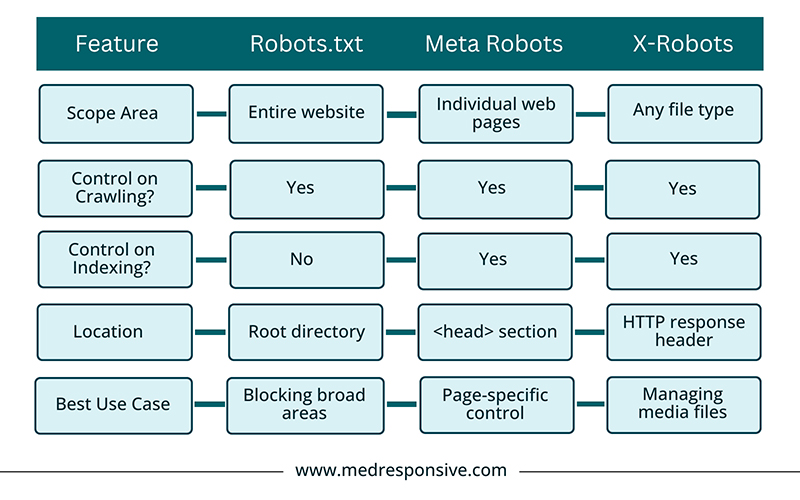
Robots.txt vs. Meta Robots vs. X-Robots
The names may make them sound complicated, but they are all essentially the same peas in a pod. Just like robots.txt, the other two are snippets of code used to guide search engines on how to handle a website’s content. However, they differ in their level of control, what they control, and their location. Let us take a look at the general differences between these concepts:
- Robots.txt: Generally considered a “gatekeeper”, robots.txt provide general instructions to search engine bots on which areas of the website they should crawl/not crawl. Robots.txt files are located in the website’s root directory.
- Meta Robots: A page-level indexing control tool, these codes are generally found within the section of individual webpages. They provide page-specific commands to crawlers, whether to index the pages or follow its links.
- X-Robots: These code snippets are added to HTTP response headers, allowing control and index at the server level. It is primarily used for non-HTML files like images and PDFs or for pages where adding a metatag is not possible.

How Robots.txt Works
When search engine bots crawl webpages, they discover and follow links. However, if they stumble upon a robots.txt file, it will read the instructions and act accordingly. If the file says, “Do not crawl this segment”, most bots (good ones) will comply, while the spam bots (bad ones)will ignore the command.
What is the Role of Robots.txt in SEO?
These lines of codes play a pivotal role in how search engines interact with your website and hence, dictating the search rankings and SEO performance. Now, let us break down its role in SEO:
- Controlling the Crawl Budget: “Crawl budget” refers to the number of pages a search engine’s bots crawl within a specific timeframe.
If your website’s number of pages exceeds the crawl budget, the bots will waste its time crawling through low-ranked/unindexed pages, like admin content or duplicate pages. This means, important pages will not be indexed and your audience will not see your website.
Robots.txt will help weed out those irrelevant pages and let the bots crawl and index important pages, thereby boosting your website’s search ranking for critical keywords.
- Preventing Duplication Issues: Duplicate content is an infamous SEO killer. If your website has multiple versions of the same content, crawlers will have a hard time figuring out which page to index and rank.
Robots.txt can address this issue by restricting crawlers from accessing these kinds of pages, thereby preserving your website’s dominance and credibility in search results.
- Avoid Indexing Irrelevant Content: Every page on the website needn’t be indexed—thank you pages, login pages or outdated content can negatively impact your SEO performance.
Therefore, it is best to block these pages to maintain a clean and a focused search engine presence, that can boost overall user experience and click-through rates.
- Enhancing Website Speed and Performance: Every search engine bot visits demand server resources. If bots spend their time crawling through unnecessary pages, it could have a detrimental effect on your server’s performance.
Robots.txt can mitigate this issue by redirecting bots to crawl only the essential parts of your website, helping maintain a faster and smoother website experience.
- Google Mobile-First Indexing: Enhancing mobile-first indexing can help crawlers accurately interpret your website’s mobile version. A well-written robots.txt file can encourage bots to access only essential elements, such as CSS & JS files, thereby making sure the website appears functional across all devices.
- Boosting Strategic SEO Campaigns: During campaigns involving launching new pages or seasonal promotional content, it is important to temporarily restrict, or enable access to certain pages. Robots.txt grants that flexibility to adapt crawling behaviour with your marketing goals.
Robots.txt in Action
Below are some of the real-time examples to demonstrate how top websites use robots.txt effectively to accomplish their objectives:
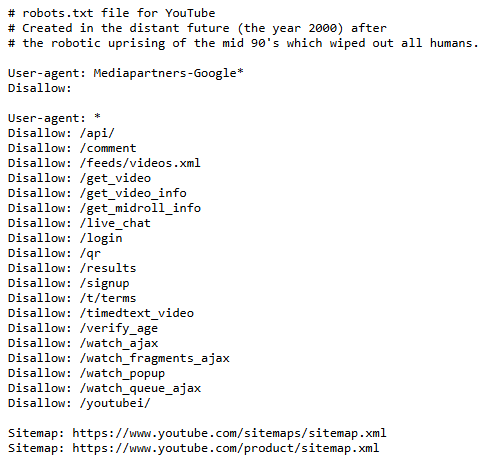
- YouTube: YouTube’s robots.txt restricts the crawling of scripts and unnecessary resources, retargeting bots on content-rich areas.

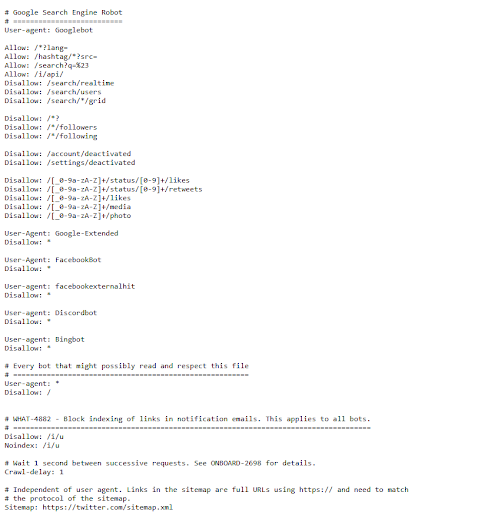
- Twitter: Twitter’s is extensive, owing to the size of its platform. It primarily restricts crawlers from accessing private areas, such as internal scripts or login endpoints.

- Google: There is no better example to demonstrate precision when it comes to robots.txt. It expertly blocks private/irrelevant areas, while guiding the bots to public-facing areas.
Visit: https://www.google.com/robots.txt
Robots.txt might be a few lines of cryptic code, but it is no mystery that it plays a pivotal role in shaping your website’s online visibility. If you learn the nuances involved, you will be able to guide the search engine crawlers exactly to where you’d want them to go and at the same time, safeguard your sensitive elements and leverage your SEO efforts.
- Controlling the Crawl Budget: “Crawl budget” refers to the number of pages a search engine’s bots crawl within a specific timeframe.